
Tensorboard On Train_on_batch
运行下列代码
Don't Copy All Elements Of A Large Rdd To The Driver.
If your RDD is so large that all of it’s elements won’t fit in memory on the drive machine, don’t do this:
内存溢出
转来的文章
Hive不能多进程操作的问题
笔者目前遇到一个问题,当开启两个ipython进程的时候会遇到下列错误
Use The Value Of Spark.sql.warehouse.dir As The Warehouse Location Instead Of Using Hive.metastore.warehouse.dir
坑的介绍在这里
从spark2.0开始,spark不再加载‘hive-site.xml'中的设置,也就是说,hive.metastore.warehouse.dir的设置无效。
spark.sql.warehouse.dir的默认值为System.getProperty("user.dir")/spark-warehouse,需要在spark的配置文件core-site.xml中设置
Hive安装
1.安装JAVA
Yarn Maximum Allocation Mb
报错如下:
[Stage 2:=============================> (1 + 1) / 2]17/06/09 06:48:54 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Container marked as failed: container_1496990795119_0001_02_000002 on host: slave1. Exit status: -1000. Diagnostics: Could not obtain block: BP-1759922210-172.31.7.59-1496717496059:blk_1073744745_3921 file=/user/ubuntu/.sparkStaging/application_1496990795119_0001/py4j-0.10.4-src.zip org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1759922210-172.31.7.59-1496717496059:blk_1073744745_3921 file=/user/ubuntu/.sparkStaging/application_1496990795119_0001/py4j-0.10.4-src.zip
Replicas Less
报错如下:
17/06/09 10:21:42 WARN scheduler.TaskSetManager: Lost task 3.0 in stage 1.0 (TID 4, slave1, executor 4): org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1759922210-172.31.7.59-1496717496059:blk_1073746824_6000 file=/user/ubuntu/data_path/training_set.parquet/part-00005-4499448f-ac1c-41bd-940c-448f6174663d.snappy.parquet
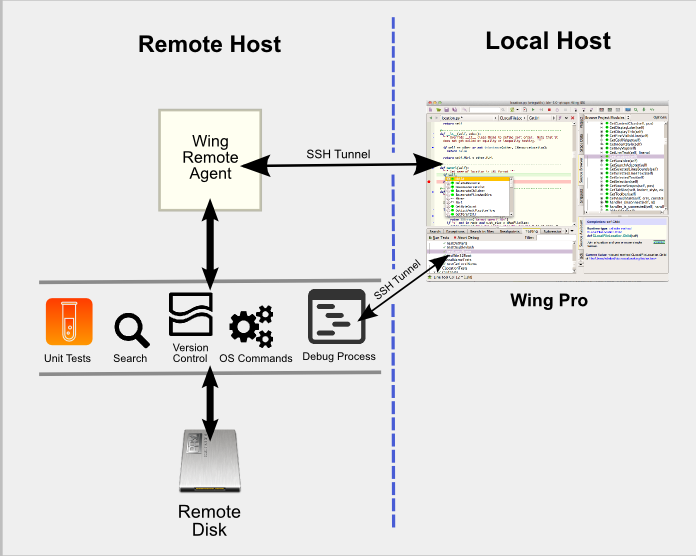
使用wingide进行远程调试
wingide远程调试架构如下
Not An Element Of Tensor Graph
错误:TypeError: Cannot interpret feed_dict key as Tensor: Tensor Tensor(“Placeholder_2:0”, shape=(500, 500), dtype=float32) is not an element of this graph.
Hadoop Import Error
错误如下
Hadoop Datanode Problem
Hadoop Datanode问题排除一
查看datanode的logs–http://slave:50075/logs/yarn-ubuntu-nodemanager-ip-172-31-0-241.log